- Home
- Download
- Buy
- Features
- How it works
- FAQ
- Contact
- Media coverage
- For Android
- For Linux
- For macOS
- Tutorials
- How to recover photos from a memory card
- How to recover photos from a USB drive
- Recovering data from SSD drives
- How to recover documents from a USB drive
- How to recover deleted files from a hard drive
- How to recover files deleted from the Recycle Bin
- Create ISO images
- Custom heuristics guide
- Custom heuristics catalog
Custom heuristics guide
DiskDigger now supports custom heuristics, meaning that you can make DiskDigger scan for any type of file (even files that aren't supported internally by the program) by creating a Custom Filter that tells DiskDigger how to find the file type you're looking for.
You can create one or more Custom Filters by creating a file called custom.xml. This file must be in the same directory as the DiskDigger executable.
The syntax of the custom.xml file looks like this:
<?xml version="1.0"?><diskdigger>
<customfilter>
<extension>MyExtension</extension>
<description>Description of this file format</description>
<beginbytes type="ascii" offset="0">BeginBytes</beginbytes>
<endbytes type="hex" offset="0">01020304</endbytes>
</customfilter>
<customfilter>
<extension>AnotherExtension</extension>
<description>Another description</description>
<beginbytes type="ascii" offset="0">Test1234</beginbytes>
<size offset="8" width="4" endian="little" adjust="8" />
<customfilter>
...
</diskdigger>
As you can see, the file contains one or more <customfilter> elements, each of which describes a custom file format.
Basically, DiskDigger only needs two pieces of information to recover a file: a starting sequence of bytes, and the size of the data that follows it (or alternatively an ending byte sequence).
The starting byte sequence is expressed using the <beginbytes> tag. The contents of this tag can be written as an ASCII string (type="ascii") or a string of hexadecimal numbers (type="hex"). The "offset" attribute specifies the byte offset where the specified byte sequence should be found. If the "offset" is set to -1, then DiskDigger will search the entire sector for the specified byte sequence, instead of expecting it at a certain offset.
The ending byte sequence is expressed using the <endbytes> tag. This tag's contents can similarly be written as an ASCII string or hex values.
Some file formats embed the actual size of the file somewhere in the file header. In this case, you can use the <size> tag instead of the <endbytes> tag. The <size> tag contains the following attributes: "offset" tells the offset from the beginning of the file where the embedded file size occurs; "width" specifies the byte width of the embedded file size (some file sizes might be 4 bytes, 8 bytes, etc); "endian" specifies the byte order of the embedded size (can be "big" or "little"); and "adjust" specifies how much to add or subtract from the embedded size (some files embed the total size minus the header, or something similar).
If a <size> tag is provided, then a <endbytes> tag is not necessary.
Both the <size> and <endbytes> tags are optional. However, if you don't provide either, DiskDigger won't know how much data to recover for your file type, so it will ask you to manually enter how many bytes you want to save.
The <extension> tag provides the file extension that you would like to use for this file type, and the <description> tag provides a short description of the file format. Both of these are optional.
Example
Let's suppose that DiskDigger did not have support for the PNG image format. Here is how we would implement this file type using a custom filter
<?xml version="1.0"?>
<diskdigger>
<customfilter>
<extension>png</extension>
<description>Portable Network Graphics</description>
<beginbytes type="hex">89504E47</beginbytes>
<endbytes type="hex">49454E44AE426082</endbytes>
</customfilter>
</diskdigger>
Let's break down what the above tags mean. We know that a PNG file begins with a byte sequence of 89 50 4E 47, so we write a <beginbytes> tag with the contents "89504E47", and a "type" attribute set to "hex".
We also know that a PNG file ends with a byte sequence of 49 45 4E 44 AE 42 60 82, so we similarly write a <endbytes> tag with the contents "49454E44AE426082", and the "type" attribute also set to "hex".
We could have also written the tags using "ascii" notation, since we know that the beginning sequence of bytes contains the letters "PNG", and the ending sequence contains the letters "IEND":
<beginbytes type="ascii" offset="1">PNG</beginbytes>
<endbytes type="ascii" offset="4">IEND</endbytes>
In the above tags, notice that there's also an "offset" attribute. In the beginning tag, it means that the specified sequence occurs 1 byte after the beginning of the file, and in the ending tag, it means that the sequence occurs 4 bytes before the end of the file.
One more example
Now let's suppose that DiskDigger did not have support for the WAV audio format. Here is how we would implement this file type using a custom filter:
<?xml version="1.0"?>
<diskdigger>
<customfilter>
<extension>wav</extension>
<description>Wave audio</description>
<beginbytes type="ascii" offset="8">WAVEfmt</beginbytes>
<size offset="4" width="4" endian="little" adjust="8" />
</customfilter>
</diskdigger>
We know that a WAV file contains the characters "WAVEfmt", which appear 8 bytes from the beginning of the file, so we write exactly that in the <beginbytes> tag.
We also know that a WAV file has its own size embedded at an offset of 4 bytes from the beginning of the file. We express this using a <size> tag with an "offset" of 4. We also know that the embedded size is 4 bytes wide, and little-endian. In addition, the embedded size is actually 8 bytes short of the total file size (it doesn't take into account the first 8 bytes of the file, which is the RIFF header), so we include an "adjust" attribute to compensate for this.
More examples
Refer to the Custom Heuristics Catalog page for a list of custom file types that have already been implemented!
Making sure it's working
To be certain that DiskDigger is actually using your custom filter, make sure the custom.xml file is in the same directory as the DiskDigger executable, and launch the program in "deeper" mode.
Your custom filter(s) should show up in the list of supported file types:
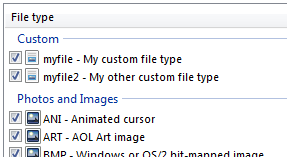
If your filter does not show up in the list, then you may have an error in the formatting of the XML file. DiskDigger should display errors if it detects any inconsistencies in your custom filters.
Considerations
There are several things to keep in mind when using custom filters:
- The beginning and/or ending byte sequence shouldn't be too short. Generally it should be at least four bytes or more. If the beginning sequence is too short, you'll likely get thousands of false positive results. And if the ending sequence is too short, your recovered files will probably be truncated prematurely.
- Before using your custom filter, make sure to test it on a known existing file of the correct type. For example, take a newly-formatted flash drive and load just that file onto it, then make sure that DiskDigger can detect it using your filter.